Application: XRD Crystal Structure Prediction#
Now that we know how to create and train neural networks in PyTorch, let’s get some practice applying them to solve an important problem in solid state crystallography: predicting crystal symmetries (in particular, the crystal space group) from powder x-ray diffraction patterns.
X-Ray Diffraction (XRD)#
X-ray crystallography is a powerful technique for characterizing the arrangement of atoms in solid structure, first introduced by Paul Ewald and Max von Laue in 1912. It has since been applied to estimate the lattice constants of crystalline solids, and even to obtain the structure of complex organic molecules, such as proteins.
In X-ray crystallography, an X-ray beam is focused into a crystalline material, causing the beam to diffract from the periodically arranged nuclei at specific angles \(\theta\). These diffraction angles \(\theta\) are given by Bragg’s diffraction law
where \(\lambda\) is the wavelength of the incident beam, \(n\) is a small integer (the diffraction order), and \(d\) is the distance between two planes of atoms in the material.
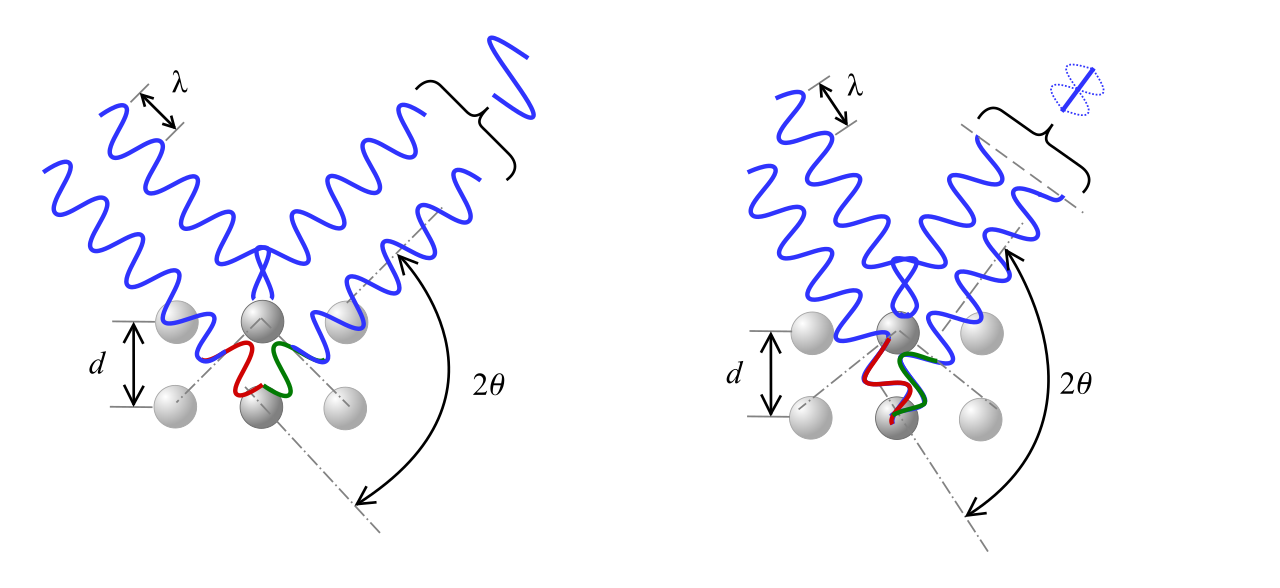
For each material, there are many different values of \(n\) and \(d\) that satisfy Bragg’s law, forming diffraction “peaks” at several different angles \(\theta\). The angle and intensity of these peaks depend on the symmetries and lattice constants of a material; however reverse-engineering the full 3D structure of a crystal from these peaks is known to be an exceptionally difficult problem.
In this application, we will attempt to use simple neural networks to predict the space group of known materials from their XRD spectrum. The space group of a material describes all of the symmetries of the material’s crystal lattice. For three dimensional materials, there are up to 230 unique space groups our neural network will need to identify based on XRD data alone.
You can download the compressed dataset for this section using the following Python code:
import requests
CSV_URL = 'https://raw.githubusercontent.com/cburdine/materials-ml-workshop/main/MaterialsML/neural_networks/xrd_dataset_full.csv.gz'
r = requests.get(CSV_URL)
with open('xrd_dataset_full.csv.gz', 'wb') as f:
f.write(r.content)
Alternatively, you can download the compressed CSV file directly here.
Loading the Dataset#
We will begin by loading the X-ray diffraction dataset into a Pandas dataframe object from the compressed file. Since this dataset has already been cleaned, we will not need to do any additional processing of the dataframe entries. To get an understanding of the data features, we can view the dataframe using the display() function:
Show code cell source
import pandas as pd
# load compressed dataset into a pandas DataFrame:
COMPRESSED_XRD_CSV = 'xrd_dataset_full.csv.gz'
data_df = pd.read_csv(COMPRESSED_XRD_CSV, compression='gzip')
# show dataframe in notebook:
display(data_df)
| mp_id | formula | composition | crystal_system | symmetry_symbol | cell_params | energy_above_hull | xray_peaks | xray_intensities | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | mp-676840 | Ag13(PbO3)6 | {'Ag': 26, 'Pb': 12, 'O': 36} | triclinic | P1 | (6.002268, 10.397799745616618, 19.466327337319... | 0.007080 | [4.539,8.504,9.086,9.625,9.662,12.428,12.486,1... | [2.848,0.094,6.001,3.006,2.908,4.037,4.086,46.... |
| 1 | mp-685283 | Ag13Bi15I64 | {'Ag': 13, 'Bi': 15, 'I': 64} | triclinic | P1 | (8.894472385608267, 9.034189542918936, 59.5692... | 0.083551 | [1.485,2.970,4.455,5.941,7.429,8.917,10.407,11... | [100.000,0.282,0.843,0.044,0.360,0.059,2.260,0... |
| 2 | mp-1229151 | Ag15S5I4Br | {'Ag': 15, 'S': 5, 'I': 4, 'Br': 1} | triclinic | P1 | (6.993913570662637, 8.558995140558554, 10.9872... | 0.065281 | [8.805,10.757,11.873,13.371,13.441,15.703,16.3... | [0.410,0.293,0.217,0.223,0.179,0.159,0.162,0.1... |
| 3 | mp-759792 | Ag2B8O13 | {'Ag': 8, 'B': 32, 'O': 52} | triclinic | P1 | (7.898226, 10.663953129513134, 12.038956354262... | 0.011548 | [7.451,8.414,10.253,11.203,12.162,13.467,13.46... | [2.472,0.055,0.002,0.459,0.076,33.647,27.434,8... |
| 4 | mp-686742 | Ag2H21N7(ClO4)2 | {'Ag': 2, 'H': 21, 'N': 7, 'Cl': 2, 'O': 8} | triclinic | P1 | (8.185132, 8.714175033958062, 9.08744340539081... | 0.700030 | [10.854,10.961,11.426,11.674,14.809,15.183,15.... | [8.524,100.000,65.581,91.596,2.314,4.840,1.231... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 91140 | mp-1364038 | Zn3Si3(SnO6)2 | {'Zn': 24, 'Si': 24, 'Sn': 16, 'O': 96} | cubic | Ia-3d | (12.35908, 12.35908, 12.35908, 90.0, 90.0, 90.0) | 0.308748 | [17.577,20.324,26.994,28.897,32.396,34.024,35.... | [5.740,45.839,4.501,67.368,55.614,0.429,100.00... |
| 91141 | mp-1163950 | Zn3Si3(WO6)2 | {'Zn': 24, 'Si': 24, 'W': 16, 'O': 96} | cubic | Ia-3d | (12.137336, 12.137336, 12.137336, 90.0, 90.0, ... | 0.226553 | [17.901,20.699,27.497,29.436,33.005,34.665,36.... | [3.294,74.831,2.346,56.137,25.406,0.374,100.00... |
| 91142 | mp-1327509 | Zn3Sn2(GeO4)3 | {'Zn': 24, 'Sn': 16, 'Ge': 24, 'O': 96} | cubic | Ia-3d | (12.573034, 12.573034, 12.573034, 90.0, 90.0, ... | 0.227320 | [17.276,19.974,26.526,28.395,31.830,33.428,34.... | [0.201,16.587,0.840,64.249,87.208,4.704,100.00... |
| 91143 | mp-648774 | Zr2Cl5 | {'Zr': 96, 'Cl': 240} | cubic | Ia-3d | (21.790819064017104, 21.790819064017104, 21.79... | 0.059570 | [9.943,11.486,15.213,16.271,18.207,19.104,19.9... | [0.626,100.000,6.746,1.780,0.009,2.667,4.761,0... |
| 91144 | mp-531184 | Zr6NCl15 | {'Zr': 96, 'N': 16, 'Cl': 240} | cubic | Ia-3d | (21.44328662, 21.44328662, 21.44328662, 90.0, ... | 0.000000 | [10.104,11.673,15.462,16.536,18.504,19.416,20.... | [0.389,100.000,5.158,0.569,0.025,1.852,1.828,0... |
91145 rows × 9 columns
Here is a summary of the features included in the dataset:
mp_id: Materials Project ID of material
formula: Chemical formula
composition: Composition of the material’s conventional unit cell
crystal_system: The crystal system of the material’s conventional unit cell
symmetry_symbol: The space group symmetry symbol of the material’s conventional unit cell
cell\params: The parameters of the conventional unit cell of the form \((a,b,c,\alpha, \gamma, \beta)\), where
\(a,b,c\) are the lattice constants of the unit cell.
\(\alpha, \beta, \gamma\) are angles between the lattice vectors, in degrees.
energy_above_hull: The estimated energy above the convex hull of stable materials, in eV/atom. The higher this number, the more unstable the material is.
xray_peaks: A list of ideal X-ray diffraction peak angles (units of $\(2\theta\), where \(2\theta\) is in degrees). The peaks are sampled between \(0^{\circ} < 2\theta < 90^{\circ}\). Here, we assume that a standard Copper K-alpha radiation source is used (\(\lambda \approx 1.54\) Å).
xray_intensities: A list of intensities of each X-ray diffraction peak, on a scale of 0.0 to 100.0 (arbitrary units).
Preprocessing Data#
As we have done in our previous applications, let’s determine the set of unique elements, crystal systems, and symmetry symbols represented in our dataset, which will be helpful for converting our data to a vectorized for. We will save these unique values to the variables ELEMENTS, CRYSTAL_SYSTEMS and SYMM_SYMBOLS respectively.
import ast # parses Python literals from text
# Generate a list of elements in the dataset:
ELEMENTS = set()
for v in data_df['composition'].values:
ELEMENTS |= set(ast.literal_eval(v).keys())
ELEMENTS = sorted(ELEMENTS)
# Generate a list of the crystal systems in the dataset:
CRYSTAL_SYSTEMS = sorted(set(data_df['crystal_system']))
# Generate a list of the symmetry symbols:
SYMM_SYMBOLS = sorted(set(data_df['symmetry_symbol']))
# print the sizes of ELEMENTS and CRYSTAL_SYSTEMS
print('Number of elements:', len(ELEMENTS))
print('Number of symmetry symbols:', len(SYMM_SYMBOLS))
print('Number of crystal systems:', len(CRYSTAL_SYSTEMS))
Number of elements: 88
Number of symmetry symbols: 228
Number of crystal systems: 7
In total, there are 88 elements represented in the dataset, with 7 different crystal systems. For all distinct crystal systems, the configuration of the atoms in the conventional unit cell can be arranged such that their 3D symmetries are characterized by one of the 230 space groups in three dimensions. In our dataset, we have 228 of these 230 distinct space groups represented. Each of the space groups in our dataset is uniquely represented by a symbol in Hermann-Mauguinn Notation:
print(SYMM_SYMBOLS)
Show code cell output
['Aea2', 'Aem2', 'Ama2', 'Amm2', 'C2', 'C2/c', 'C2/m', 'C222', 'C222_1', 'Cc', 'Ccc2', 'Ccce', 'Cccm', 'Cm', 'Cmc2_1', 'Cmce', 'Cmcm', 'Cmm2', 'Cmme', 'Cmmm', 'F-43c', 'F-43m', 'F222', 'F23', 'F432', 'F4_132', 'Fd-3', 'Fd-3c', 'Fd-3m', 'Fdd2', 'Fddd', 'Fm-3', 'Fm-3c', 'Fm-3m', 'Fmm2', 'Fmmm', 'I-4', 'I-42d', 'I-42m', 'I-43d', 'I-43m', 'I-4c2', 'I-4m2', 'I222', 'I23', 'I2_12_12_1', 'I2_13', 'I4', 'I4/m', 'I4/mcm', 'I4/mmm', 'I422', 'I432', 'I4_1', 'I4_1/a', 'I4_1/acd', 'I4_1/amd', 'I4_122', 'I4_132', 'I4_1cd', 'I4_1md', 'I4cm', 'I4mm', 'Ia-3', 'Ia-3d', 'Iba2', 'Ibam', 'Ibca', 'Im-3', 'Im-3m', 'Ima2', 'Imm2', 'Imma', 'Immm', 'P-1', 'P-3', 'P-31c', 'P-31m', 'P-3c1', 'P-3m1', 'P-4', 'P-42_1c', 'P-42_1m', 'P-42c', 'P-42m', 'P-43m', 'P-43n', 'P-4b2', 'P-4c2', 'P-4m2', 'P-4n2', 'P-6', 'P-62c', 'P-62m', 'P-6c2', 'P-6m2', 'P1', 'P2', 'P2/c', 'P2/m', 'P222', 'P222_1', 'P23', 'P2_1', 'P2_1/c', 'P2_1/m', 'P2_12_12', 'P2_12_12_1', 'P2_13', 'P3', 'P312', 'P31c', 'P31m', 'P321', 'P3_1', 'P3_112', 'P3_121', 'P3_2', 'P3_212', 'P3_221', 'P3c1', 'P3m1', 'P4', 'P4/m', 'P4/mbm', 'P4/mcc', 'P4/mmm', 'P4/mnc', 'P4/n', 'P4/nbm', 'P4/ncc', 'P4/nmm', 'P4/nnc', 'P422', 'P42_12', 'P4_1', 'P4_122', 'P4_12_12', 'P4_132', 'P4_2', 'P4_2/m', 'P4_2/mbc', 'P4_2/mcm', 'P4_2/mmc', 'P4_2/mnm', 'P4_2/n', 'P4_2/nbc', 'P4_2/ncm', 'P4_2/nmc', 'P4_2/nnm', 'P4_222', 'P4_22_12', 'P4_232', 'P4_2bc', 'P4_2cm', 'P4_2mc', 'P4_2nm', 'P4_3', 'P4_322', 'P4_32_12', 'P4_332', 'P4bm', 'P4cc', 'P4mm', 'P4nc', 'P6/m', 'P6/mcc', 'P6/mmm', 'P622', 'P6_1', 'P6_122', 'P6_2', 'P6_222', 'P6_3', 'P6_3/m', 'P6_3/mcm', 'P6_3/mmc', 'P6_322', 'P6_3cm', 'P6_3mc', 'P6_4', 'P6_422', 'P6_5', 'P6_522', 'P6cc', 'P6mm', 'Pa-3', 'Pba2', 'Pbam', 'Pban', 'Pbca', 'Pbcm', 'Pbcn', 'Pc', 'Pca2_1', 'Pcc2', 'Pcca', 'Pccm', 'Pccn', 'Pm', 'Pm-3', 'Pm-3m', 'Pm-3n', 'Pma2', 'Pmc2_1', 'Pmm2', 'Pmma', 'Pmmm', 'Pmmn', 'Pmn2_1', 'Pmna', 'Pn-3', 'Pn-3m', 'Pn-3n', 'Pna2_1', 'Pnc2', 'Pnma', 'Pnn2', 'Pnna', 'Pnnm', 'Pnnn', 'R-3', 'R-3c', 'R-3m', 'R3', 'R32', 'R3c', 'R3m']
The space groups of materials can be partitioned into mutually exclusive groups based on their corresponding crystal system. We can build the mapping of symmetry symbols to their associated crystal system by populating a Python dictionary:
# Generate a map from each symmetry symbol to
# the corresponding crystal system
SYMM_SYMBOL_MAP = {}
for _, row in data_df.iterrows():
system = row['crystal_system']
symm = row['symmetry_symbol']
SYMM_SYMBOL_MAP[symm] = system
Visualizing the XRD Spectrum#
To gain a better understanding of what an X-ray diffraction spectrum looks like, we will need to first write some Python functions to parse the XRD peaks and intensities from each row of our dataframe. Then, we will need to write a function that plots the XRD spectrum. We give you the Python code for these two functions below.
import matplotlib.pyplot as plt
def parse_xrd_data(row):
peaks = ast.literal_eval(row['xray_peaks'])
ints = ast.literal_eval(row['xray_intensities'])
return peaks, ints
def plot_xrd(peaks, intensities):
plt.figure()
for x, y in zip(peaks, intensities):
plt.plot([x,x], [0, y], color='b', linewidth=2)
plt.axhline(color='b')
plt.xlim((0,90))
plt.grid()
plt.ylabel('Intensity [arb. units]')
plt.xlabel(r'Diffraction Angle $2\theta$ [degrees]')
plt.show()
Let’s now visualize the X-ray diffraction spectrum for an example material in our dataset:
example_idx = 1234
peaks, intensities = parse_xrd_data(data_df.iloc[example_idx])
plot_xrd(peaks, intensities)
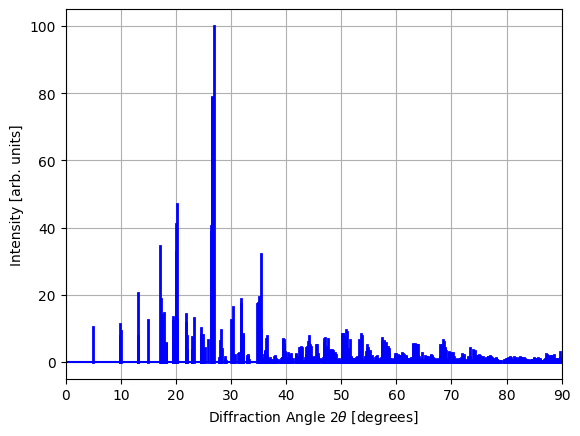
In our dataset, the diffraction patterns correspond to large crystals, which is why we observe very sharp peaks in the spectrum. In practice, however, such sharp peaks are rarely observed due to the finite sizes of the crystals used in experimental settings. (This finite-size effect is known as Scherrer broadening).
To convert each XRD spectrum to a feature vector that can serve as input to a neural network, we will use a histogram-based representation of the X-ray diffraction data. Specifically, we will divide the spectrum into a finite number of “bins” and normalize each “bin” by dividing by the maximum peak intensity (which is 100 for this dataset). We will also write a function to convert the symmetry group symbols to a vector representation using the same “one-hot” encoding that we have used in previous applications.
import numpy as np
def vectorize_xrd_spectrum(peaks, intensities, intensity_scale=100, bins=90):
hist, _ = np.histogram(
peaks, bins=bins,
range=(0, 90),
weights=intensities)
return hist / intensity_scale
def vectorize_symmetry(symmetry_symbol, symbols):
""" converts a symmetry symbol to a vector. """
vec = np.zeros(len(symbols))
if symmetry_symbol in symbols:
vec[symbols.index(symmetry_symbol)] = 1.0
return vec
Next, we will write a function to parse each row of the dataframe return an \(\mathbf{x}\) vector (the histogram of the XRD spectrum) and a \(\mathbf{y}\) vector (the space group of the material).
def parse_data_vector(row):
""" parses x and y vectors from a dataframe row """
# parse the xray peaks and intensities
peaks, ints = parse_xrd_data(row)
# parse feature vector (x):
x_vector = vectorize_xrd_spectrum(peaks, ints)
# parse label vector (y):
y_vector = vectorize_symmetry(
row['symmetry_symbol'], symbols=SYMM_SYMBOLS)
return x_vector, y_vector
Compiling the Dataset#
Now that we have functions that can parse each row in our dataframe, let’s write a dataset class called XRDDataset that extends the PyTorch Dataset class (torch.utils.data.Dataset). Since the dataset may take a long time to compile we will add a progress bar using the tqdm package, so that we can see how long the dataset will take to compile.
from torch.utils.data import Dataset
from tqdm import tqdm
# Define a custom dataset class
class XRDDataset(Dataset):
def __init__(self, xrd_df):
data_x = []
data_y = []
# parse data from datafrane
for _, row in tqdm(xrd_df.iterrows(), total=len(xrd_df)):
x, y = parse_data_vector(row)
data_x.append(x)
data_y.append(y)
np_data_x = np.array(data_x)
np_data_y = np.array(data_y)
# convert data to pytorch tensors
self.data_x = torch.tensor(np_data_x, dtype=torch.float32)
self.data_y = torch.tensor(np_data_y, dtype=torch.float32)
def __len__(self):
""" returns the size of this dataset"""
return len(self.data_x)
def __getitem__(self, idx):
""" Gets the (x,y) pair at index 'idx' """
x = self.data_x[idx]
y = self.data_y[idx]
return x, y
Next, we will create an XRDDataset instance and split it into training, validation, and test sets.
from torch.utils.data import random_split
# compile dataset
dataset = XRDDataset(data_df)
# split dataset into training, validation, and test sets
train_dataset, val_dataset, test_dataset = \
random_split(dataset, [0.8, 0.1, 0.1])
XRDNet Model#
After compiling the dataset, our next step is to define our model. Here, we will use a simple feed-forward neural network but with a configurable number of layers with user-specified sizes. This will allow us to explore different model architectures and determine which architecture yields the best results.
To define our model, we will extend the torch.nn.Module class, creating our own class called XRDNet. This class will have a constructor that takes the following arguments:
input_size: The size of the model’s input vectors (the number of XRD spectrum “bins”).hidden_layer_sizes: A list of sizes corresponding to the size of the hidden feature vectors for each hidden layer.output_size: The size of the model’s output vector (the number of space groups).
Extending the nn.Module class requires us to define the forward() function, which is called when an instance of the model class is called as if it were a Python function. For the forward() function, we will output a vector of numbers corresponding to the log-likelihoods that the XRD spectrum is associated with the corresponding space group. We will also add a function called classify() that returns a vector where the most likely space group is assigned a value close to \(1\), and all other space groups are assigned values close to \(0\). (This is achieved using the nn.SoftMax() activation function, which maintains differentiability of the model weights with respect to the output of classify()).
import torch
import torch.nn as nn
# Define the neural network class (XRDNet)
class XRDNet(nn.Module):
def __init__(self, input_size, hidden_layer_sizes, output_size):
""" Constructs a feed-forward neural network with many hidden layers"""
super().__init__()
layer_sizes = [input_size]
layer_sizes.extend(hidden_layer_sizes)
layer_sizes.append(output_size)
self.hidden_layers = nn.ParameterList([
nn.Linear(size_in, size_out)
for size_in, size_out in
zip(layer_sizes[:-1], layer_sizes[1:])
])
# define hidden layer activation function:
self.activation = nn.SiLU()
# use the softmax activation (only when classifying)
self.out_activation = nn.Softmax(dim=-1)
def forward(self, x):
""" Estimates the log-likelihood of each output feature"""
for layer in self.hidden_layers[:-1]:
x = self.activation(layer(x))
out = self.hidden_layers[-1](x)
return out
def classify(self, x):
""" Estimates the normalized output probability of each output feature"""
out = self.forward(x)
return self.out_activation(out)
It will also be helpful to create some functions that evaluate the model’s loss function and overall model accuracy for an entire dataset:
def eval_model_loss(model, data_loader, loss_fn):
loss = []
with torch.no_grad():
for z_batch, y_batch in data_loader:
loss.append(loss_fn(model(z_batch), y_batch))
mean_loss = torch.stack(loss).mean().item()
return mean_loss
def eval_model_accuracy(model, data_loader):
acc = []
with torch.no_grad():
for z_batch, y_batch in data_loader:
pred_class = model.classify(z_batch).argmax(dim=-1)
true_class = y_batch.argmax(dim=-1)
acc.append((pred_class == true_class).to(torch.float32).mean())
mean_acc = torch.stack(acc).mean().item()
return mean_acc
Let’s go ahead and create an instance of our XRDNet class:
model = XRDNet(
input_size=len(dataset[0][0]),
hidden_layer_sizes= [512, 512, 256, 128],
output_size=len(dataset[0][1]),
)
Fitting the Model#
In order to fit our model to the training dataset, we will have to write some code to perform our main training loop. To simplify the fitting process, we will wite a function fit_model() with the following arguments:
model: The classification model we are fitting.train_dataset: The training dataset we are fitting to.val_dataset: The validation dataset we will use to compare to the training loss during the fitting process.n_epochs: The number of epochs used during training. Recall that during each epoch, the batch gradient descent algorithm iterates over each item in the training dataset once.batch_size: The batch size used in the batch gradient descent algorithm. Recall that the batch size corresponds to how many items in the dataset are included in each weight update step.lr: The learning rate \(\eta\) used during batch gradient descent.wd: The weight decay regularization factor, which is the coefficient sum-of-squares penalty applied to the loss function. (When weight decay is used, you should use theAdamWoptimizer instead of the regularAdamoptimizer).
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
def fit_model(model, train_dataset, val_dataset, n_epochs=100, batch_size=64, lr=1e-3, wd=1e-3):
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
optimizer = optim.AdamW(model.parameters(), lr=lr, weight_decay=wd)
loss_fn = nn.CrossEntropyLoss()
# create a dict to record losses during training
history = {
'train_loss': [],
'val_loss': [],
'train_acc': [],
'val_acc': []
}
# main training loop (fixed number of epochs)
for epoch in range(n_epochs):
# apply stochastic gradient descent step to each batch in dataset
print(f'Epoch {epoch}')
epoch_losses = []
for z_batch, y_batch in tqdm(train_loader):
# zero optimizer gradients
optimizer.zero_grad()
# generate batch prediction
y_hat_batch = model(z_batch)
# compute loss
loss = loss_fn(y_hat_batch, y_batch)
epoch_losses.append(loss.item())
# backpropagate loss
loss.backward()
optimizer.step()
# evaluate epoch training and validation losses:
train_loss = eval_model_loss(model, train_loader, loss_fn)
val_loss = eval_model_loss(model, val_loader, loss_fn)
# evaluate epoch accuracies:
train_acc = eval_model_accuracy(model, train_loader)
val_acc = eval_model_accuracy(model, val_loader)
print(f'Train loss: {train_loss}; Val loss: {val_loss}')
print(f'Train acc: {train_acc}; Val acc: {val_acc}')
# record losses in history dictionary
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
return history
Finally, let’s fit our model to the training dataset, monitoring the training and validation set accuracies after each epoch. Running the following code mat take a bit, but you should be able to see the training set error decreasing after each epoch. In order to minimize the validation set loss of the model and optimize training speed, you may need to adjust the following settings:
Increase
n_epochsif the validation set has not yet converged to a plateau; decrease it if the validation loss starts to increase.Increase
batch_sizeif the model training is too slow. (This will only increase training speed up to a point).Decrease
lrif the training set loss is varying too much between epochs or starts increasing.Increase
wdif the training error drops much faster than the validation set error (a consequence of overfitting). Your goal should be to avoid overfitting while achieving the lowest possible validation error during the last epoch. However, ifwdis set too high, the model may slightly underfit the data.
You might also consider changing the overall model architecture (e.g.,increasing/decreasing the number of layers or layer sizes if the model is underfitting/overfitting).
Here are some good training parameters to start with:
history = fit_model(
model,
train_dataset,
val_dataset,
batch_size=512,
n_epochs=40,
lr=1e-3,
wd=1e-1
)
Evaluating Model Performance#
For each training run, you will want to take a look at the training and validation errors on the same axes to see how well the model is performing. We plot the training and validation loss using the code below.
plt.figure()
plt.plot(history['train_loss'], label='Training Set')
plt.plot(history['val_loss'], label='Validation Set')
plt.ylabel('CrossEntropy Loss')
plt.xlabel('Epoch')
plt.grid()
plt.legend()
plt.show()

Likewise, we plot the model accuracy using the code below.
plt.figure()
plt.plot(history['train_acc'], label='Training Set')
plt.plot(history['val_acc'], label='Validation Set')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.legend()
plt.show()

Once we have a good idea of the optimal parameters that minimize the validation set loss (thereby maximizing the model accuracy), we should obtain our final estimate of the model accuracy by evaluating it on the test set:
train_acc = eval_model_accuracy(model, train_dataset)
val_acc = eval_model_accuracy(model, val_dataset)
test_acc = eval_model_accuracy(model, test_dataset)
print(f'Train Accuracy: {train_acc:.6f}')
print(f'Validation Accuracy: {val_acc:.6f}')
print(f'Test Accuracy: {test_acc:.6f}')
Train Accuracy: 0.534087
Validation Accuracy: 0.452052
Test Accuracy: 0.458964
Above, we have obtained an accuracy of only 0.45 on the training set; however this is still a statistically significant improvement upon randomly guessing each class with accuracy \(1/228 \approx 0.004\).