Kernel Machines#
In this section, we will introduce a powerful and popular class of regression and classification models known as kernel machines. Kernel machines are an extension of the high-dimensional embedding models of the form:
As we will see, kernel machines can even be used to compute functions where \(D_{emb} = \infty\) (i.e. the data is embedded in an infinite-dimensional space). This is achieved through computing only the inner products between data points, given by a kernel function \(K(\mathbf{x}, \mathbf{x}')\).
Maximum Absolute Error Regression:#
In order to understand kernel functions, it is helpful to first examine the problem of maximum absolute error regression. The goal of this regression model is to find the simplest high-dimensional embedding model (i.e. the one with the minimal sum of weights squared) subject to the constraint that the maximum absolute error of all predictions in the training set lie within an error tolerance value \(\varepsilon\). Formally, we write this optimization problem as:
This is an instance of a Lagrange multiplier problem, which we can re-write in standard form.
Note: Lagrange Multiplier Problems
A Lagrange multiplier problem is an optimization problem concerning the optimization of an objective function \(f\) subject to a set of constraint functions \(g\). Such a problem is in standard form, if it can be written as follows:
The Lagrangian of this problem is the function:
where the \(\lambda_i\) are variables called Lagrange multipliers. It can be shown that all local minima and maxima of \(f(\mathbf{w})\) must satisfy the equation:
This equation, along with the constraints \(g(\mathbf{w})\) can be used to determine the multipliers \(\lambda_i\) and the associated points \(\mathbf{w}\) where \(f\) attains local maxima and minima. Under certain regularity conditions (see Slater’s condition) it can be shown that the local minima of the problem correspond to solutions of the dual optimization problem:
Writing the maximum absolute error regression problem in the standard form of a Lagrange multiplier problem, we obtain:
Note that we have added a coefficient of \(1/2\) to the objective function, which does not affect the solution to the optimization problem. In total, this problem has \(k=2N\) constraint functions, which means that we must introduce a total of \(2N\) Lagrange multipliers. Letting \(\alpha_1, \alpha_2, ..., \alpha_n\) and \(\alpha_1^*, \alpha_2^*, ..., \alpha_n^*\) be the Lagrange multipliers of the top and bottom set of constraints respectively, the Lagrangian function with respect to the weights \(\mathbf{w}\) is:
Important
A couple of notation warnings for physicists:
The notation \(\alpha_n^*\) does not denote the complex conjugate here; the Lagrange multipliers \(\alpha_n\) and \(\alpha_n^*\) are independent real scalar values.
The “Lagrangian” function used here is unrelated to the Lagrangian operator \(\mathcal{L} = \mathcal{T} - \mathcal{V}\), though both of these formalisms are attributed to Lagrange. (Same guy, different crime).
Setting the gradient of the Lagrangian equal to \(\mathbf{0}\), we obtain an expression for the weights \(\mathbf{w}\):
To ensure a solution exists to our optimization problem, we impose the following additional constraints on the Lagrange multipliers:
The first constraint follows from \(\nabla_w\mathcal{L}(\mathbf{w}) = \mathbf{0}\), while the second constraint bounds the Lagrange multipliers by a regularization parameter \(C\). After imposing these constraints and eliminating \(\mathbf{w}\) from the Lagrangian, we obtain the following dual formulation of the problem (which we have re-written as a minimization problem):
Above \(\mathbf{G} = \mathbf{\Phi}(\mathbf{X})^T\mathbf{\Phi}(\mathbf{X})\) and \(\mathbf{a} = \begin{bmatrix} (\alpha_0 - \alpha_0^*) & (\alpha_1 - \alpha_1^*) & \dots & (\alpha_N - \alpha_N^*) \end{bmatrix}^T\). The matrix \(\mathbf{G}\) is called a Gram matrix. It is a symmetric \(N \times N\) matrix containing the inner product of every data point \(\mathbf{x}\) with every other data point \(\mathbf{x}\) in the embedding space. The function that computes this inner product is called a kernel function \(K: \mathcal{X} \times \mathcal{X} \rightarrow \mathbb{R}_{\ge 0}\). Specifically, the entries of \(\mathbf{G}\) are given by:
where the kernel function \(K(\mathbf{x},\mathbf{x}')\) is defined as:
While the kernel function \(K(\mathbf{x},\mathbf{x}')\) can be concretely interpreted as the inner product of \(\mathbf{x}\) and \(\mathbf{x}'\) in the embedding space, we can abstractly think of \(K\) as a measure of “similarity” between two points \(\mathbf{x}\) and \(\mathbf{x}'\). The higher the value of \(K(\mathbf{x},\mathbf{x}')\), the more similar \(\mathbf{x}\) is to \(\mathbf{x}'\).
Important
In most software packages, the \(y_1,y_2, ..., y_N\) values are standardized prior to solving the dual problem to ensure that \(w_0 = 0\) (this ensures that the regularization parameter \(C\) does not bound the bias weight \(w_0\)). Because \(w_0 = 0\), the leading column of \(1\)s in the embedding matrix \(\mathbf{\Phi}(\mathbf{X})\) is unnecessary, and is thus removed. This results in a Gram matrix \(\mathbf{G}\) with entries:
Solving the dual formulation of the maximum absolute error regression problem can be accomplished through one of a number of algorithms, such as the sequential minimal optimization (SMO) algorithm.
Support Vectors#
From studying the maximum absolute error regression problem, we found that the optimal weights \(w_i\) satisfy the relationship \(w_i = \sum_n (\alpha_n - \alpha_n^*)\phi_i(\mathbf{x}_n)\). Using the definition of the kernel function \(K(\mathbf{x},\mathbf{x}')\), we find that that we can re-write an embedding model in terms of a sum of the kernel function applied to each data point \(\mathbf{x}_n\) in the training dataset:
This is an important result, as it allows us to quantitatively measure the “importance” of each datapoint \(\mathbf{x}_n\) in training the model by examining the values of \((\alpha_n - \alpha_n^*)\). Furthermore, it also allows us quantify how each of the training datapoints \(\mathbf{x}_n\) contribute to predictions made on an unseen datapoint \(\mathbf{x}\). This contribution is the product of \((\alpha_n - \alpha_n^*)\) (the “importance” of \(\mathbf{x}_n\)) and \(K(\mathbf{x}_n,\mathbf{x})\) (the “similarity” of \(\mathbf{x}_n\) and \(\mathbf{x}\)).
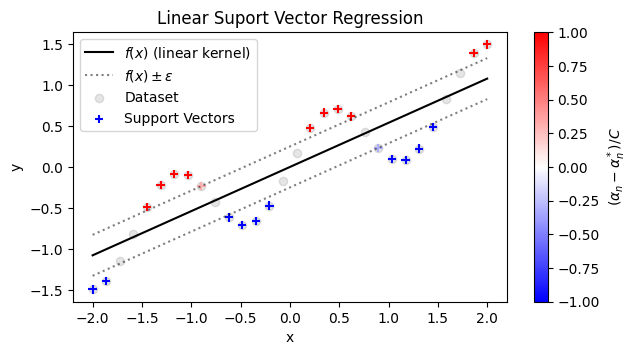
Recall that the \(\alpha_n\) and \(\alpha_n^*\) are Lagrange multipliers corresponding to the constraint \(|f(\mathbf{x}_n) - y_n| \le \varepsilon\). In Lagrange multiplier problems, if the optimal solution has \(\lambda_i = 0\) for any multiplier \(\lambda_i\), it means that the solution does not lie on the boundary of the corresponding constraint \(g_i(\mathbf{w}) = 0\). So, if \(\alpha_n = \alpha_n^* = 0\), it means that the constraint \(|\hat{y} - y| < \epsilon\) was not necessary in fitting the model. In other words, the points with \(|(\alpha - \alpha^*)| > 0\) are the only points that were “important” in finding the best fit of the model. These points are called support vectors. In the simple case of a linear model, the points with \((\alpha - \alpha^*) \neq 0\) are the points that lie above and below the \(f(x) \pm \varepsilon\) region, as shown in the illustration below:

Kernel Functions#
One practical trade-off that we experience when transitioning from an embedding model to an equivalent kernel-based model (often called a kernel machine) is that in order to compute a prediction \(f(\mathbf{x})\), we are shifting from a computation that involves a summation of \(D_{emb}\) terms to a computation that can involve up to \(N\) terms, where \(N\) is the size of the dataset. Fortunately, the summation only needs to carried out over the support vectors where \((\alpha_n - \alpha_n^*)\) is nonzero:
Depending on the type of the kernel function \(K\), the tolerance factor \(\varepsilon\), and the size of the dataset, the number of support vectors may be large or small. When working with kernel machines, it is common to try out multiple kernels, and select the best fit that strikes a balance between model accuracy and the number of support vectors. Below are some kernels that are commonly used:
Linear Kernel:
Polynomial Kernel (degree \(d\)):
Radial Basis Function (RBF) Kernel:
Parameterized \(L^2\) function Kernel:
Advanced Tip: Quantum Mechanics Problems and the \(L^2\) Kernel
The parameterized \(L^2\) function kernel is similar to the wave function inner product you may have encountered in a quantum mechanics course, i.e:
This kernel can be used in a variety of solid state physics problems involving the electronic structure of materials. For example, \(\mathbf{x}\) could be a vector representing a linear combination of atomic orbitals. We note, however, that additional care must be taken when working with kernel functions that are complex-valued.
Kernel machines are also currently being explored in the field of Quantum Machine Learning, which seeks to integrate quantum computation with existing classical machine learning. Quantum Kernel machines naturally make use of the \(L^2\) kernel, and appear to be promising model for predicting quantum mechanical properties of materials. Unfortunately, quantum computers have yet to reach the scale necessary to apply machine learning algorithms to large datasets.
Recall that the kernel function \(K(\mathbf{x},\mathbf{x}')\) computes the inner product of two data points embedded in \(D_{emb}\)-dimensional space. Remarkably, it can be shown that for some kernel functions, such as RBF kernel and the \(L^2\) kernel, the embedding space has dimension \(D_{emb} = \infty\)! This means that when we fit a kernel machine using these kernels, we are actually performing linear regression in an infinite dimensional space, which is impossible to do with a traditional linear regression model. This neat little result is called the “kernel trick”.
Support Vector Regression#
Although the theory of support vector regression and other types of kernel machines is quite complex, using them in practice is quite easy. The sklearn library contains a several different kernel machine models that we can integrate into our Python code. Many different kernels are also supported. For example, to fit a support vector regression model with a linear kernel, we can use sklearn.svm.SVR as shown in the following code:
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVR
# generate dataset:
data_x = np.linspace(-2,2,30)
data_y = 0.5*data_x + 0.5*np.sin(4*data_x)
# fit a linear support vector regression (SVR) model:
svr_epsilon=0.25
svr = SVR(kernel='linear', epsilon=svr_epsilon)
svr.fit(data_x.reshape(-1,1), data_y)
# evaluate SVR predictions:
eval_x = np.linspace(-2,2, 100)
eval_yhat = svr.predict(eval_x.reshape(-1,1))
# plot SVR predictions:
plt.figure(figsize=(7,3.5))
plt.plot(eval_x, eval_yhat, 'k', label=r'$f(x)$ (linear kernel)')
plt.plot(eval_x, eval_yhat+svr_epsilon, 'k:',
alpha=0.5, label=r'$f(x) \pm \varepsilon$')
plt.plot(eval_x, eval_yhat-svr_epsilon, 'k:', alpha=0.5)
plt.scatter(data_x, data_y, c='k', alpha=0.1, label='Dataset')
sv_plot = plt.scatter(data_x.take(svr.support_).flatten(),
data_y.take(svr.support_), c=svr.dual_coef_,
marker='+', cmap='bwr', label='Support Vectors')
plt.colorbar(sv_plot, label=r'$(\alpha_n - \alpha_n^*)/C$')
plt.ylabel('y')
plt.xlabel('x')
plt.title('Linear Suport Vector Regression')
plt.legend()
plt.show()
Exercises#
Exercise 1: Support Vector Regression:
Let’s play with some Support Vector Regression (SVR) models. These models are fit by solving the same maximum absolute error regression problem we discussed above. One benefit of using SVR models is that it is very easy to try different kinds of embeddings (including infinite-dimensional ones) simply by swapping out kernels.
Consider the following (randomly generated) 2D dataset:
import numpy as np
# Generate training dataset:
data_x = np.array([
np.random.uniform(0,10, 400),
np.random.uniform(-2e-2,2e-2, 400)
]).T
data_y = np.cos((data_x[:,0]-5)**2/10 + (100*data_x[:,1])**2)
Plot the dataset, and fit three different SVR models to the data with sklearn.svm.SVR. Use the following kernels:
linear kernel (
SVR(kernel='linear'))second degree polynomial kernel (
SVR(degree=2,kernel='poly'))radial basis function kernel (
SVR(kernel='rbf'))
Finally, for each kernel function, plot the prediction surface. You can do this with the following Python function:
def plot_model_predictions(data_x, model, x_scaler=None, title=None):
"""
Plots the prediction surface of a model with 2D features.
Args:
data_x: the 2D data (numpy array with shape (N,2))
model: an sklearn model (fit to standardized `data_x`)
x_scaler: an sklearn.preprocessing.StandardScaler
for standardizing the `data_x` data array
(optional)
title: title of plot (optional)
"""
mesh_x1, mesh_x2 = np.meshgrid(
np.linspace(np.min(data_x[:,0]),np.max(data_x[:,0]), 100),
np.linspace(np.min(data_x[:,1]),np.max(data_x[:,1]), 100)
)
mesh_x = np.array([ mesh_x1.flatten(), mesh_x2.flatten() ]).T
mesh_z = x_scaler.transform(mesh_x) if x_scaler else mesh_x
pred_y = model.predict(mesh_z)
mesh_yhat = pred_y.reshape(mesh_x1.shape)
plt.figure()
cnt = plt.contourf(mesh_x1, mesh_x2, mesh_yhat, levels=20)
plt.colorbar(cnt, label=r'$\hat{y}$')
plt.xlabel(r'$x_1$')
plt.ylabel(r'$x_2$')
plt.title(title if title else str(model))
plt.show()
Exercise 2: Kernel Support Vector Classification
Kernel machines can also be used for the task of classification. In this exercise, we will get some practice working with support vector classification models.
Repeat Exercise 1, but using Support Vector Classifier models (see sklearn.svm.SVC). Use the SVCs to fit the following training data:
import numpy as np
# Generate training dataset:
data_x = np.array([
np.random.uniform(0,10, 400),
np.random.uniform(-3e-2,3e-2, 400)
]).T
data_y = np.sign(3-(data_x[:,0]**(0.7) + (50*data_x[:,1])**2))
Above, data_y contains +1 values for the positive class and -1 values for the negative class. Use the same three kernels as in Exercise 1:
linear kernel (
SVC(kernel='linear'))second degree polynomial kernel (
SVC(degree=2,kernel='poly'))radial basis function kernel (
SVC(kernel='rbf'))
To plot the prediction surfaces of the classifier, you can use the same plot_model_predictions function as in Exercise 1.
Solutions#
Exercise 1: Support Vector Regression#
Show code cell content
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
# Generate training dataset:
data_x = np.array([
np.random.uniform(0,10, 400),
np.random.uniform(-2e-2,2e-2, 400)
]).T
data_y = np.cos((data_x[:,0]-5)**2/10 + (100*data_x[:,1])**2)
# plot training dataset:
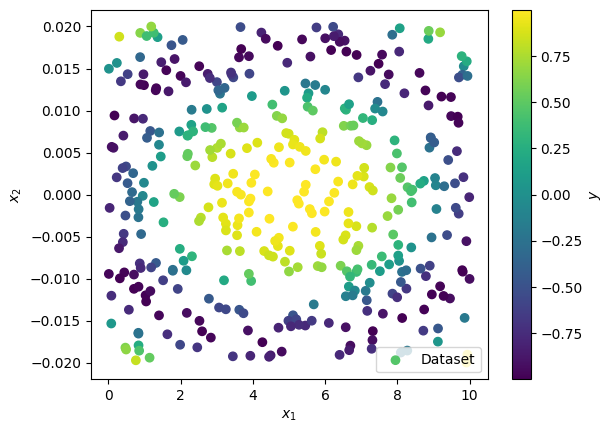
plt.figure()
sp = plt.scatter(data_x[:,0], data_x[:,1], c=data_y, label='Dataset')
plt.colorbar(sp, label=r'$y$')
plt.xlabel(r'$x_1$')
plt.ylabel(r'$x_2$')
plt.legend()
plt.show()
def plot_model_predictions(data_x, model, x_scaler=None, title=None):
"""
Plots the prediction surface of a model with 2D features.
Args:
data_x: the 2D data (numpy array with shape (N,2))
model: an sklearn model (fit to standardized `data_x`)
x_scaler: an sklearn.preprocessing.StandardScaler
for standardizing the `data_x` data array
(optional)
title: title of plot (optional)
"""
mesh_x1, mesh_x2 = np.meshgrid(
np.linspace(np.min(data_x[:,0]),np.max(data_x[:,0]), 100),
np.linspace(np.min(data_x[:,1]),np.max(data_x[:,1]), 100)
)
mesh_x = np.array([ mesh_x1.flatten(), mesh_x2.flatten() ]).T
mesh_z = x_scaler.transform(mesh_x) if x_scaler else mesh_x
pred_y = model.predict(mesh_z)
mesh_yhat = pred_y.reshape(mesh_x1.shape)
plt.figure()
cnt = plt.contourf(mesh_x1, mesh_x2, mesh_yhat, levels=20)
plt.colorbar(cnt, label=r'$\hat{y}$')
plt.xlabel(r'$x_1$')
plt.ylabel(r'$x_2$')
plt.title(title if title else str(model))
plt.show()
# fit a StandardScaler to data:
scaler = StandardScaler()
scaler.fit(data_x)
# standardize x_data:
data_z = scaler.transform(data_x)
# These are the regression models we are trying:
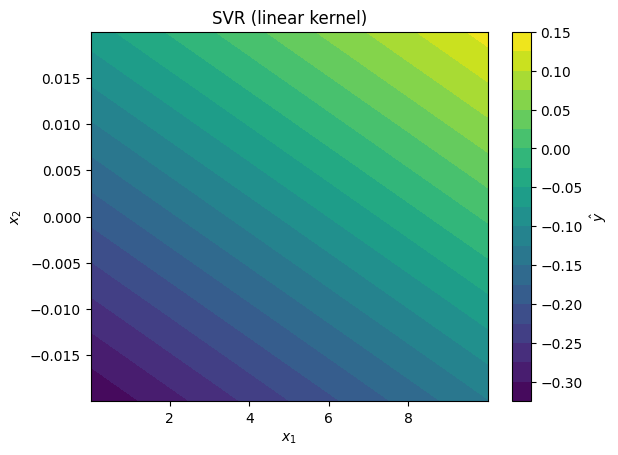
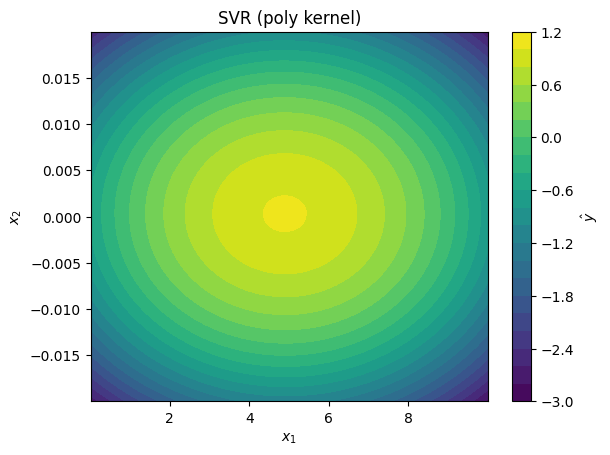
svr_models = [
SVR(kernel='linear'),
SVR(kernel='poly', degree=2),
SVR(kernel='rbf'),
]
# fit each model and plot the prediction surface:
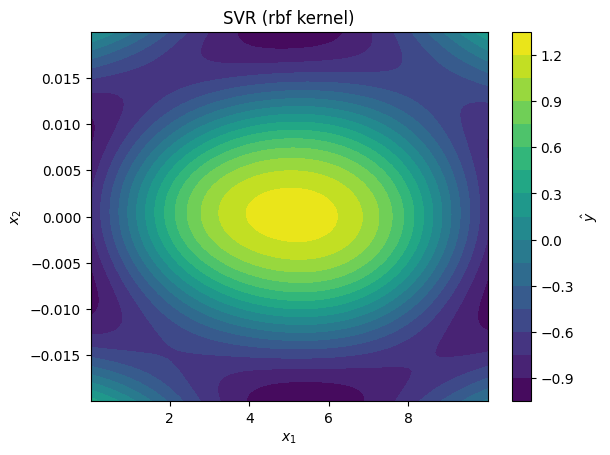
for svr_model in svr_models:
# fit model to standardize data:
svr_model.fit(data_z, data_y)
# plot predictions made by kernel SVR model
plot_model_predictions(data_x,
model=svr_model,
x_scaler=scaler,
title=f'SVR ({svr_model.kernel} kernel)')
Exercise 2: Support Vector Classification#
Show code cell content
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
# !! Note: This uses the plot_model_predictions function from Exercise 1.
# Generate training dataset:
data_x = np.array([
np.random.uniform(0,10, 400),
np.random.uniform(-3e-2,3e-2, 400)
]).T
data_y = np.sign(3-(data_x[:,0]**(0.7) + (50*data_x[:,1])**2))
# plot training dataset:
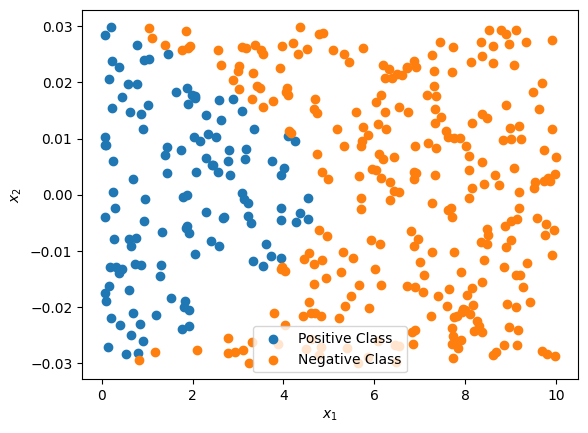
plt.figure()
plt.scatter(data_x[data_y > 0,0], data_x[data_y > 0,1], label='Positive Class')
plt.scatter(data_x[data_y < 0,0], data_x[data_y < 0,1], label='Negative Class')
plt.xlabel(r'$x_1$')
plt.ylabel(r'$x_2$')
plt.legend()
plt.show()
# fit a StandardScaler to data:
scaler = StandardScaler()
scaler.fit(data_x)
# standardize x_data:
data_z = scaler.transform(data_x)
# These are the classifier models we are trying:
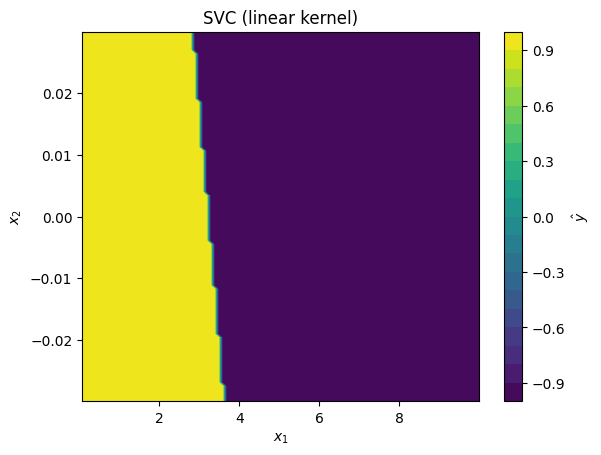
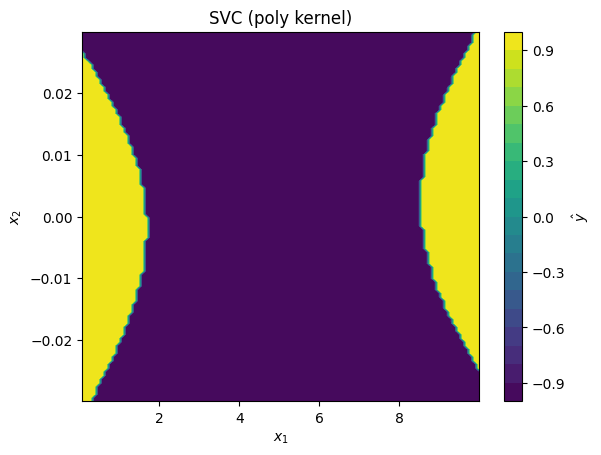
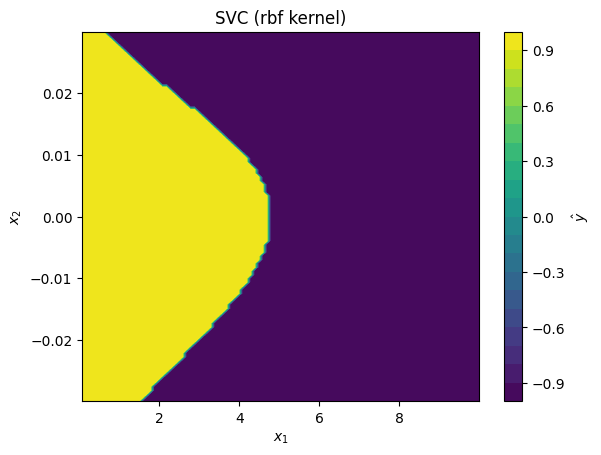
svc_models = [
SVC(kernel='linear'),
SVC(kernel='poly', degree=2),
SVC(kernel='rbf'),
]
# fit each model and plot the prediction surface:
for svc_model in svc_models:
# fit model to standardized data:
svc_model.fit(data_z, data_y)
# plot predictions made by kernel SVR model
plot_model_predictions(data_x,
model=svc_model,
x_scaler=scaler,
title=f'SVC ({svc_model.kernel} kernel)')